
If you have a blog or a website which has a ton of content, the discovery of the content is critical. Enabling users to search through your content will help in retention and acquisition. Before we look at ElasticSearch, let’s see how we can enable search with different databases.
MySQL
Say we have a table with a list of users. It will look something like below.,
| ID | NAME | |
|---|---|---|
| 1 | Tony Stark | tony@example.com |
| 2 | Flint Stone | flint@example.com |
| 3 | Ethan Hunt | ethan@example.com |
Now if we have to search for a person named Flint, the query goes like this.,
SELECT * FROM TABLE WHERE NAME LIKE '%Flint%'
Keep in mind that this query will not only return the user row of Flint Stone but also any other user rows which contain Flint in it. But the search functionality is very limited and ranking of results based on similarity is very difficult to achieve. However, you can use the MyISAM database engine instead of InnoDB in order to improve the search performance. You can do Full Text search but it will take a hit on ACID properties. If the application is transactional in nature, MyISAM is not recommended.
Let’s look at how search works in a non-relational database. Let’s take MongoDB as our database for the same user data. The data will look something like the following.,
{
"id": 1,
"name": "Tony Stark",
"email": "tony@example.com"
},
{
"id": 2,
"name": "Flint Stone",
"email": "flint@example.com"
},
{
"id": 3,
"name": "Ethan Hunt",
"email": "ethan@example.com"
}
Now in order to search, we have two options. We can just use regular expression or we use Text search. Using Regular expressions we can mimic LIKE functionality from MySQL as mentioned below.,
db.getCollection("user").find( /flint/i )
We use i in the end in order to represent the case-insensitive match. In order to perform a Text search, we need to index the collection with text index. The following command creates a text index for a given collection.
db.getCollection("user").createIndex( { name:"text" } )
If there are multiple fields which are required to be added for text index then we need to specify multiple fields. Additionally, we can also specify weights which will help in scoring while fetching results for search queries.
db.getCollection("user").createIndex({name:"text",email:"text"},{weights:{name:10,email:5}})
In order to search we perform the following query.,
db.getCollection("user").find( { $text: { $search: "flint" } } )
Check out the official documentation for more details.
Despite best efforts from MongoDB, we don’t get the best search experience possible. In both the above examples, we have indexed or queried the main database where actual data is stored. Searching and Indexing are heavy operations and this will indefinitely affect the IO operations. More rigorous operations like Autosuggestion where every keystroke of the user needs a different result will consume significant resources of traditional databases. Now let’s look at ElasticSearch.
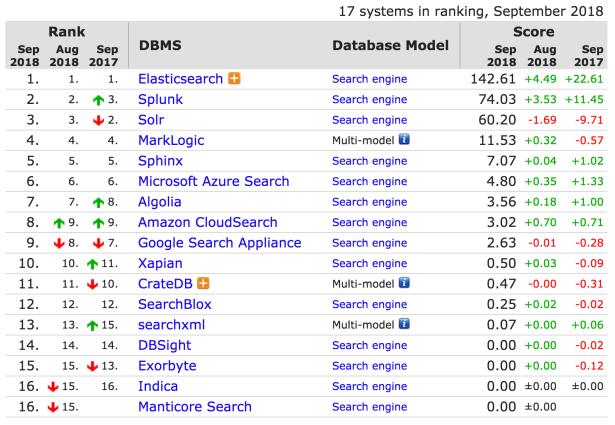
Traditionally we don’t use ElasticSearch as a primary data store. We use any database but also keep a copy of it in ElasticSearch for search and analytics purposes. If you look at the following image, you can see that ElasticSearch is considered the best for search.
We can setup ElasticSearch in 3 ways.,
- ElasticSearch is open source and hence all you have to do is download the source files and install it on a server. Refer to the documentation.
- Use AWS’s ElasticSearch Service. If you have an AWS account, you can deploy an ElasticSearch instance. Refer to the link for more details.
- Use Elastic Cloud. It’s built by people who created ElasticSearch and it provides not only Search but also Analytics and Machine Learning.
ElasticSearch once installed/deployed, can be accessed via its RESTful API. ElasticSearch follows document based modal for storing data. Let’s look at the basic things we need to do in order get it up and running.
First up we need to create an index. The name of the index is user.
PUT user
{
"settings" : {
"number_of_replicas" : 2
}
}
The curl request will look something like below.,
curl -XPUT http://domain.ap-southeast-1.es.amazonaws.com/user/_settings -d {"index":{"number_of_replicas":2}}
Once we have created an index, we need to create a mapping. Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
PUT userMap
{
"mappings": {
"doc": {
"properties": {
"name": { "type": "text" },
"email": { "type": "text" }
}
}
}
}
Now we need to add our data from our primary database to ElasticSearch.,
PUT /user/userMap/1/_create
{
"name": "Tony Stark",
"email": "tony@example.com"
}
The curl request will look something like below.,
curl -H "Content-Type: application/json" -XPOST "http://domain.ap-southeast-1.es.amazonaws.com/user/userMap/1" -d "{ \"name\" : \"Tony Stark\", \"email\" : \"tony@example.com\"}"
Finally, we need to search the database and get results.,
GET /user/userMap/_search?q=flint
The curl request will look something like below.,
curl -XGET 'http://domain.ap-southeast-1.es.amazonaws.com/user/_search?q=flint'
We get the results in JSON format along with their scores. This article only covers the basics of ElasticSearch, in order to know more please refer to the official documentation. More articles will follow on important aspects of ElasticSearch such as Authentication, CRUD operations and how to access ElasticSearch via traditional scripting languages like PHP.
Comment below if you have any doubts or queries. You can also request me to write on any particular topic which you need help with understanding.

